前言 擁有自己的 AI 大模型!開源項目 LMFlow 支持上千種模型,提供全流程高效訓練方案。
本文轉載自機器之心
僅用於學術分享,若侵權請聯系刪除
歡迎關注公眾號CV技術指南,專註於計算機視覺的技術總結、最新技術跟蹤、經典論文解讀、CV招聘信息。
CV各大方向專欄與各個部署框架最全教程整理
計算機視覺入門1v3輔導班
2022 年 11 月 30 日,OpenAI 推出 ChatGPT,令人沒想到的是,這個對話模型在 AI 圈掀起一股又一股討論狂潮。英偉達 CEO 黃仁勛將其比喻為人工智能領域的 iPhone 時刻;比爾・蓋茨盛贊 ChatGPT 在人工智能歷史上的意義不亞於 PC 或互聯網的誕生。
盡管 ChatGPT 在各個方面表現驚人,但其高昂的訓練成本以及海量的訓練數據等,都給想要進入該領域的人設下層層關卡。就拿算力來說,ChatGPT 經由微軟專門建設的 AI 計算系統訓練,總算力消耗約為 3640 PF-days。而在推理階段,以今年 1 月份獨立訪客平均數 1300 萬計算,ChatGPT 對應的芯片需求為 3 萬多塊英偉達 A100 GPU,初始投入成本約為 8 億美元,每天光是花掉的電費就要 5 萬美元。就連科技巨頭微軟在幫 OpenAI 打造 ChatGPT 時都因為算力不足而被迫暫停了一些其他項目。
科技大廠尚且如此,對於普通人來說更是難上加難。
因此在 ChatGPT 問世的這段時間裡,許多人開始對科研的方向和未來感到迷茫:如何能夠參與通用人工智能研究,在這個新的時代找到自己的優勢?很多人都希望有能力訓練一個隻屬於自己的 AI 大模型,但盡管國內外已有許多類 GPT 產品,對於普通的學者、研究者和程序員來說,這樣的產品仍不足以適應每一個人的需求。一方面,從頭預訓練的成本是我們普通人和小規模公司所無法承受的。另一方面,基於 API 的黑盒封裝不是完美的解決方案。雖然我們可以很容易地基於 API 開發自己的應用,但使用效果和自定義程度往往不盡人意。因此,從頭預訓練和基於 API 開發都不是最佳方式。
接下來我們為大家介紹的開源項目 LMFlow,不需要從頭預訓練,隻需要以 finetune 作為切入點即可。
項目地址:https://github.com/OptimalScale/LMFlow
項目介紹
該項目由香港科技大學統計和機器學習實驗室團隊發起,致力於建立一個全開放的大模型研究平臺,支持有限機器資源下的各類實驗,並且在平臺上提升現有的數據利用方式和優化算法效率,讓平臺發展成一個比之前方法更高效的大模型訓練系統。
此外,該項目的最終目的是幫助每個人都可以用盡量少的資源來訓練一個專有領域的、個性化的大模型,以此來推進大模型的研究和應用落地。
在 LMFlow 的加持下,即便是有限的計算資源,也能讓使用者針對專有領域支持個性化訓練。基於 70 億參數的 LLaMA,隻需 1 張 3090、耗時 5 個小時,就可以訓練一個專屬於自己的個性化 GPT,並完成網頁端部署。開源庫作者們已經利用這個框架單機訓練 330 億參數的 LLaMA 中文版,並開源了模型權重用於學術研究。訓練得到的模型權重可以通過該網頁端即刻體驗問答服務 (http://lmflow.com)。
http://lmflow.com 地址:http://lmflow.com/使用 LMFlow,你也有能力訓練一個隻屬於自己的模型!每個人可以根據自己的資源合理選擇訓練的模型,用於問答、陪伴、寫作、翻譯、專家領域咨詢等各種任務。模型和數據量越大,訓練時間越長,效果越佳。目前該研究也在訓練更大參數量《650 億》和更大數據量的中文版模型,效果還會持續提升。
其實,很早之前 LMFlow 的作者們就已認識到 finetune 的重要性。InstructGPT [1] 中就涵蓋了 supervised fine-tuning 和 alignment《比如 RLHF》這兩種 finetune 技術。然而,目前的開源代碼庫要麼聚焦於某個模型《比如 LLaMA [2]》,要麼聚焦於某種特定的技術《比如 instruction tuning》。還沒有一個庫能夠支持在海量模型上快速應用多種 finetune 技術。
現在,LMFlow 邁出了這個方向的第一步。通常,ChatGPT 的訓練包括至少以下幾個步驟:pretrain → supervised tuning → instruction tuning → alignment。LMFlow 庫利用現有的開源大模型,支持這套流程的所有環節和靈活組合。這意味著 LMFlow 庫為我們建立了一條通向完整訓練鏈的橋梁。

接下來我們來了解一下實際使用 LMFlow 的體驗。使用體驗
據作者介紹,LMFlow 擁有四大特性:可擴展、輕量級、定制化和完全開源。基於此,用戶可以很快地訓練自己的模型並繼續進行二次迭代。這些模型不僅限於最近流行的 LLaMA,也包括 GPT-2、Galactica 等模型。
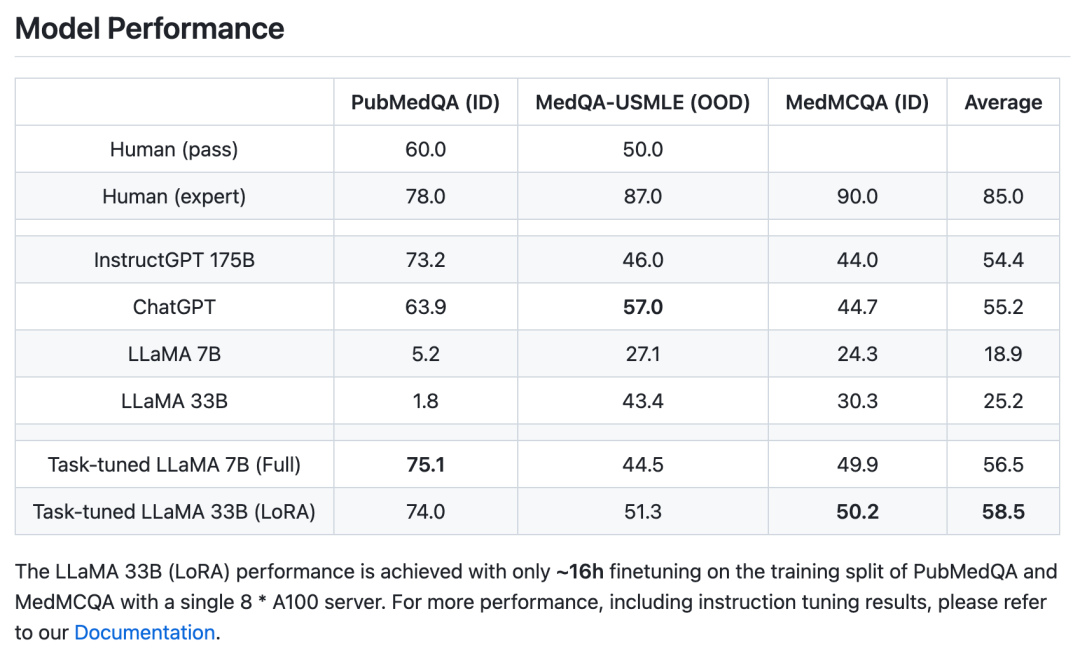
前面我們已經提到:基於該開源庫,用戶隻需使用單卡 3090,就能對 LLaMA-7b 模型進行微調,用時 5 個小時訓練得到一個能夠流暢對話的問答模型。進一步,如果使用更多資源對更大的 LLaMA-33b 模型進行微調,即可大大提升回答的質量!

不僅如此,在特定的專家領域《以醫療為例》,隻需微調 6 個 A100 * 天,就能夠獲得和 ChatGPT 相當甚至更好的效果。值得注意的是,ChatGPT 則具有 1750 億的參數量,而這裡性能相當的最小模型規模隻有不到二十分之一,大大節約計算資源。
接下來是真正的上手實驗。使用 conda 安裝必要的依賴後,即可上手體驗。

安裝和準備數據集的過程非常順利,如此便捷是因為作者們貼心地提供了一鍵下載數據集的方式。隻需要運行一個 bash 腳本就能下載所需的數據集,非常方便!

準備好了數據集之後,接下來就是模型訓練。訓練過程也大大簡化,普通用戶隻需要執行一次 bash 腳本,即可輕松完成《非常適合小白入坑》。作者們還開放了訓練好的模型下載,如果你不想自己訓練模型,可以下載作者提供的 checkpoint 並進行推理。

在此基礎上,作者們還提供了基於 huggingface 模型或本地 checkpoint 的問答機器人腳本。一鍵運行即可與你訓練的模型開始對話:

如果在使用過程中遇到任何問題,歡迎通過 github issue 或 github 主頁的微信群聯系作者團隊。
在當下大家都紛紛投入到預訓練大模型的競賽中時,LMFlow 提供了一個很好的啟示:大多數普通玩家沒有預訓練大模型的資源,但仍舊可以參與到這場使用和研究大模型的浪潮中來。正如他們的口號所說:「讓每個人都能訓得起大模型《Large Language Model for All》。」
參考文獻
[1] Ouyang,Long,et al. "Training language models to follow instructions with human feedback." Advances in Neural Information Processing Systems 35 (2022): 27730-27744.
[2] Touvron,Hugo,et al. "Llama: Open and efficient foundation language models." arXiv preprint arXiv:2302.13971 (2023).
歡迎關注公眾號CV技術指南,專註於計算機視覺的技術總結、最新技術跟蹤、經典論文解讀、CV招聘信息。
計算機視覺入門1v3輔導班
『技術文檔』《從零搭建pytorch模型教程》122頁PDF下載
QQ交流群:470899183。群內有大佬負責解答大家的日常學習、科研、代碼問題。
其它文章
上線一天,4k star | Facebook:Segment Anything
Efficient-HRNet | EfficientNet思想+HRNet技術會不會更強更快呢?
實踐教程|GPU 利用率低常見原因分析及優化
ICLR 2023 | SoftMatch: 實現半監督學習中偽標簽的質量和數量的trade-off
目標檢測創新:一種基於區域的半監督方法,部分標簽即可《附原論文下載》
CNN的反擊!InceptionNeXt: 當 Inception 遇上 ConvNeXt
神經網路的可解釋性分析:14種歸因算法
無痛漲點:目標檢測優化的實用Trick
詳解PyTorch編譯並調用自定義CUDA算子的三種方式
深度學習訓練模型時,GPU顯存不夠怎麼辦?
deepInsight:一種將非圖像數據轉換圖像的方法
ICLR2023|基於數據增廣和知識蒸餾的單一樣本訓練算法
拯救脂肪肝第一步!自主診斷脂肪肝:3D醫療影像分割方案MedicalSeg
AI最全資料匯總 | 基礎入門、技術前沿、工業應用、部署框架、實戰教程學習
改變幾行代碼,PyTorch煉丹速度狂飆、模型優化時間大減
AAAI 2023 | 輕量級語義分割新范式: Head-Free 的線性 Transformer 結構
TSCD:弱監督語義分割新方法,中科院自動化所和北郵等聯合提出
如何用單個GPU在不到24小時的時間內從零開始訓練ViT模型?
CVPR 2023 | 基於Token對比的弱監督語義分割新方案!
比MobileOne還秀,Apple將重參數與ViT相結合提出FastViT
CVPR 2023 | One-to-Few:沒有NMS檢測也可以很強很快
ICLR 2023 | Specformer: Spectral GNNs Meet Transformers
重新審視Dropout
計算機視覺入門1v3輔導班
計算機視覺交流群
聊聊計算機視覺入門